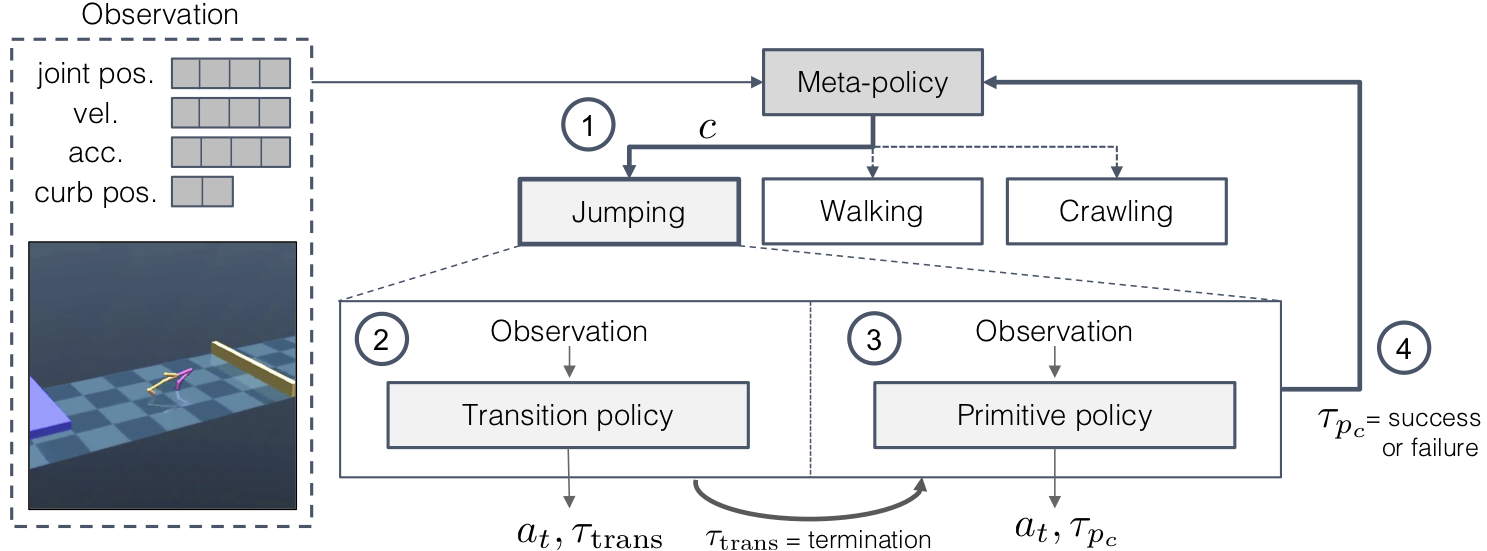
Humans acquire complex skills by exploiting previously learned skills and making transitions between them.
To empower machines with this ability, we propose a method that can learn transition policies which effectively connect primitive skills to perform sequential tasks without handcrafted rewards.
To efficiently train our transition policies, we introduce proximity predictors which induce rewards gauging proximity to suitable initial states for the next skill.
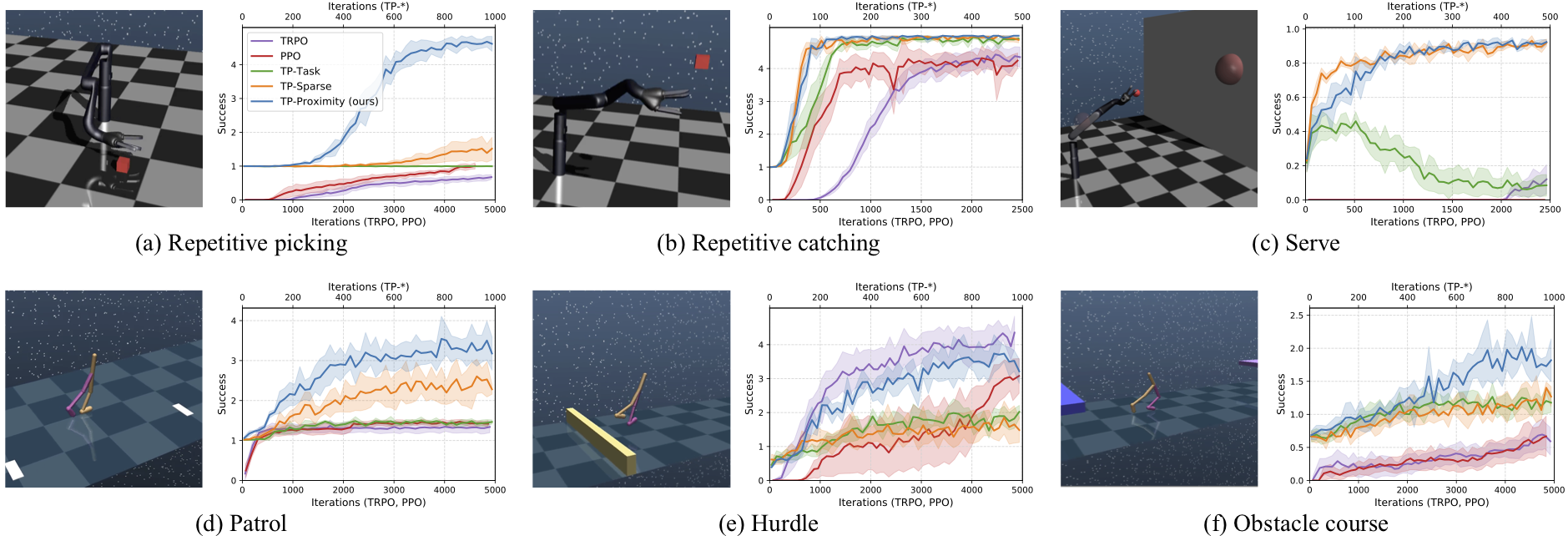
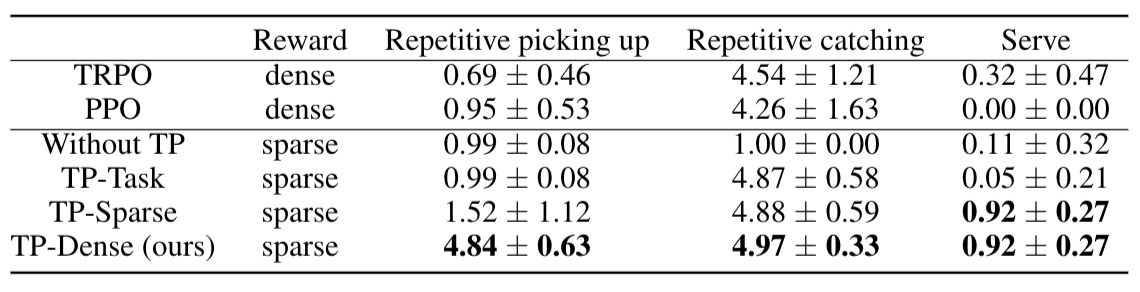
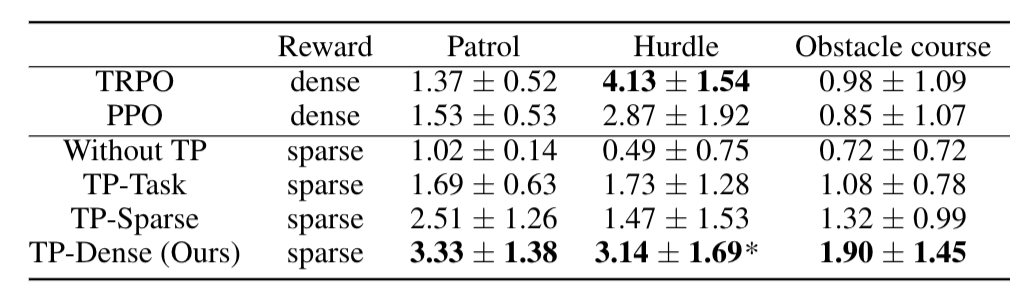
The proposed method is evaluated on a set of complex continuous control tasks in bi-pedal locomotion and robotic arm manipulation which traditional policy gradient methods struggle at.
We demonstrate that transition policies enable us to effectively compose complex skills with existing primitive skills.
The proposed induced rewards computed using the proximity predictor further improve training efficiency by providing more dense information than the sparse rewards from the environments.
This tough environment requires the agent to walk, jump and crawl its way to success.
Inspired by tennis, this task is composed of tossing and hitting a ball to a target.
Similar to a guard patrol, the agent must walk forwards and backwards repeatedly.
We have released the TensorFlow based implementation on the github page. Try our code!